
Résumé du webinaire : Comment Insurely a intégré des agents vocaux à son centre de contact
- Catégorie
- Produit
- Date
Scribe v2 est le modèle Speech to Text le plus précis. Scribe v2 Realtime établit la référence pour les transcriptions en direct - alimentant les agents et les applications en temps réel. Tous deux disponibles via API.


Scribe v2 Realtime capture la parole en direct en moins de 150 ms avec une précision exceptionnelle – conçu pour les agents, les réunions et les agents IA qui exigent une compréhension instantanée.
Scribe v2 Realtime offre une précision leader dans l'industrie avec une latence inférieure à 150 ms, établissant une nouvelle référence pour la reconnaissance vocale en temps réel.
Détectez automatiquement quand la parole commence et s'arrête, segmentant la parole avec précision pour un traitement en direct plus fluide.
Offrant une précision exceptionnelle à travers les accents, dialectes et conditions d'enregistrement.
Intégrez Scribe Realtime v2 dans vos produits avec l'API. Avec prise en charge complète du streaming et contrôle des engagements.


Téléchargez de l'audio ou de la vidéo dans n'importe quel format — MP4, MOV, MP3, WAV, et plus. Scribe v2 convertit automatiquement la parole en texte précis, prêt pour les légendes, sous-titres ou l'édition.
Scribe v2 atteint une précision de transcription leader dans l'industrie, offrant un texte propre et éditable même dans des conditions audio difficiles ou à travers divers accents.
Sélectionnez jusqu’à 1000 mots ou phrases pour que Scribe les retranscrive précisément selon le contexte.
Du rire aux pas, Scribe v2 étiquette chaque événement sonore, enrichissant vos transcriptions avec le contexte complet.
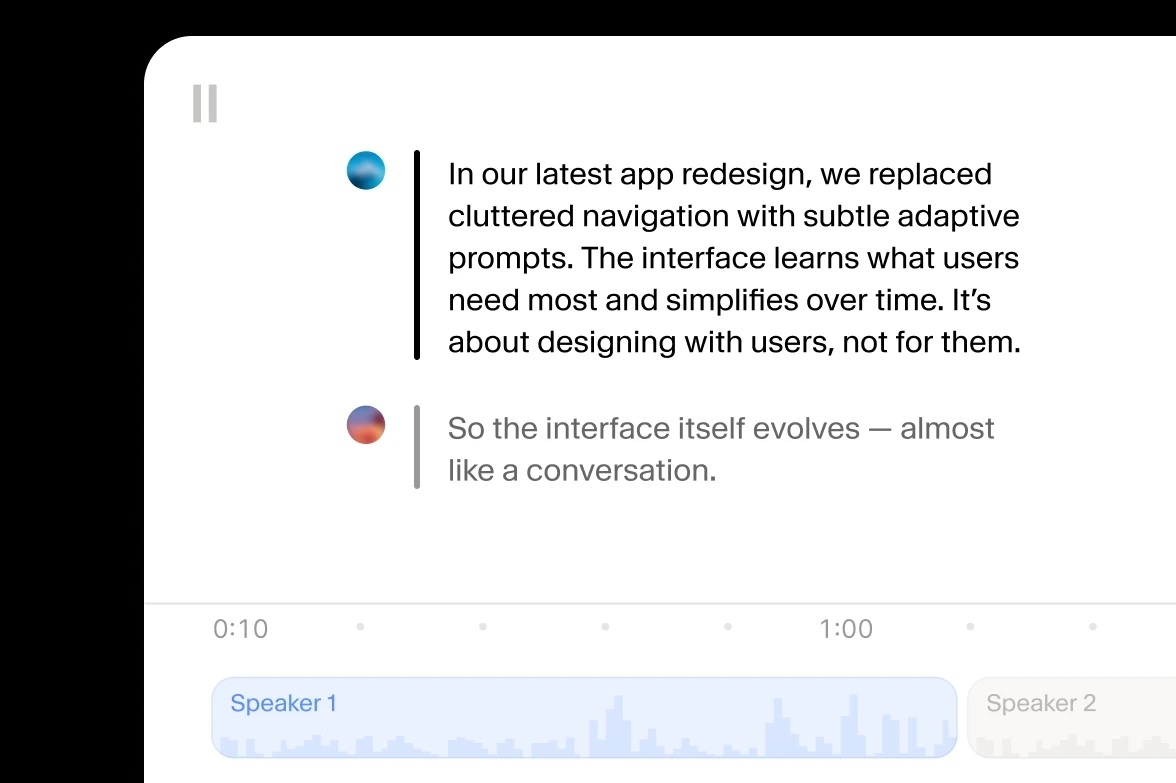
Scribe v2 distingue intuitivement et étiquette chaque locuteur et calcule les horodatages des entités.
Intégrez Scribe v2 et Scribe v2 Realtime dans votre produit avec l'API ou les SDKs.

Activez les interactions vocales en temps réel avec une transcription instantanée et à faible latence.
.webp&w=3840&q=100)
Convertissez les enregistrements en texte éditable, légendes et contenu réutilisable.
Notre transcription AI Speech to Text prend en charge plus de 90 langues, il suffit de sélectionner la langue et de télécharger votre fichier audio.













































































