Models
Flagship models
Text to Speech
Our most emotionally rich, expressive speech synthesis model
Lifelike, consistent quality speech synthesis model
Our fast, affordable speech synthesis model
Speech to Text
State-of-the-art speech recognition model
Real-time speech recognition model
Music
Models overview
The ElevenLabs API offers a range of audio models optimized for different use cases, quality levels, and performance requirements.
Deprecated models
The eleven_monolingual_v1 and eleven_multilingual_v1 models are deprecated and will be removed in the future. Please migrate to newer models for continued service.
The eleven_turbo_v2_5 and eleven_turbo_v2 models are functionally equivalent to the
eleven_flash_v2_5 and eleven_flash_v2 models respectively, except the latency on the Flash
models is lower on average. We recommend using the Flash models over Turbo models in all use
cases.
Eleven v3
Eleven v3 is our latest and most advanced speech synthesis model. It is a state-of-the-art model that produces natural, life-like speech with high emotional range and contextual understanding across multiple languages.
This model works well in the following scenarios:
- Character Discussions: Excellent for audio experiences with multiple characters that interact with each other.
- Audiobook Production: Perfect for long-form narration with complex emotional delivery.
- Emotional Dialogue: Generate natural, lifelike dialogue with high emotional range and contextual understanding.
With Eleven v3 comes a new Text to Dialogue API, which allows you to generate natural, lifelike dialogue with high emotional range and contextual understanding across multiple languages. Eleven v3 can also be used with the Text to Speech API to generate natural, lifelike speech with high emotional range and contextual understanding across multiple languages.
Read more about the Text to Dialogue API here.
Supported languages
The Eleven v3 model supports 70+ languages, including:
Afrikaans (afr), Arabic (ara), Armenian (hye), Assamese (asm), Azerbaijani (aze), Belarusian (bel), Bengali (ben), Bosnian (bos), Bulgarian (bul), Catalan (cat), Cebuano (ceb), Chichewa (nya), Croatian (hrv), Czech (ces), Danish (dan), Dutch (nld), English (eng), Estonian (est), Filipino (fil), Finnish (fin), French (fra), Galician (glg), Georgian (kat), German (deu), Greek (ell), Gujarati (guj), Hausa (hau), Hebrew (heb), Hindi (hin), Hungarian (hun), Icelandic (isl), Indonesian (ind), Irish (gle), Italian (ita), Japanese (jpn), Javanese (jav), Kannada (kan), Kazakh (kaz), Kirghiz (kir), Korean (kor), Latvian (lav), Lingala (lin), Lithuanian (lit), Luxembourgish (ltz), Macedonian (mkd), Malay (msa), Malayalam (mal), Mandarin Chinese (cmn), Marathi (mar), Nepali (nep), Norwegian (nor), Pashto (pus), Persian (fas), Polish (pol), Portuguese (por), Punjabi (pan), Romanian (ron), Russian (rus), Serbian (srp), Sindhi (snd), Slovak (slk), Slovenian (slv), Somali (som), Spanish (spa), Swahili (swa), Swedish (swe), Tamil (tam), Telugu (tel), Thai (tha), Turkish (tur), Ukrainian (ukr), Urdu (urd), Vietnamese (vie), Welsh (cym).
Multilingual v2
Eleven Multilingual v2 is our most advanced, emotionally-aware speech synthesis model. It produces natural, lifelike speech with high emotional range and contextual understanding across multiple languages.
The model delivers consistent voice quality and personality across all supported languages while maintaining the speaker’s unique characteristics and accent.
This model excels in scenarios requiring high-quality, emotionally nuanced speech:
- Character Voiceovers: Ideal for gaming and animation due to its emotional range.
- Professional Content: Well-suited for corporate videos and e-learning materials.
- Multilingual Projects: Maintains consistent voice quality across language switches.
- Stable Quality: Produces consistent, high-quality audio output.
While it has a higher latency & cost per character than Flash models, it delivers superior quality for projects where lifelike speech is important.
Our multilingual v2 models support 29 languages:
English (USA, UK, Australia, Canada), Japanese, Chinese, German, Hindi, French (France, Canada), Korean, Portuguese (Brazil, Portugal), Italian, Spanish (Spain, Mexico), Indonesian, Dutch, Turkish, Filipino, Polish, Swedish, Bulgarian, Romanian, Arabic (Saudi Arabia, UAE), Czech, Greek, Finnish, Croatian, Malay, Slovak, Danish, Tamil, Ukrainian & Russian.
Flash v2.5
Eleven Flash v2.5 is our fastest speech synthesis model, designed for real-time applications and Agents Platform. It delivers high-quality speech with ultra-low latency (~75ms†) across 32 languages.
The model balances speed and quality, making it ideal for interactive applications while maintaining natural-sounding output and consistent voice characteristics across languages.
This model is particularly well-suited for:
- Agents Platform: Perfect for real-time voice agents and chatbots.
- Interactive Applications: Ideal for games and applications requiring immediate response.
- Large-Scale Processing: Efficient for bulk text-to-speech conversion.
With its lower price point and 75ms latency, Flash v2.5 is the cost-effective option for anyone needing fast, reliable speech synthesis across multiple languages.
Flash v2.5 supports 32 languages - all languages from v2 models plus:
Hungarian, Norwegian & Vietnamese
† Excluding application & network latencyConsiderations
Text normalization with numbers
When using Flash v2.5, numbers aren’t normalized by default in a way you might expect. For example, phone numbers might be read out in way that isn’t clear for the user. Dates and currencies are affected in a similar manner.
By default, normalization is disabled for Flash v2.5 to maintain the low latency. However, Enterprise customers can now enable text normalization for v2.5 models by setting the apply_text_normalization parameter to “on” in your request.
The Multilingual v2 model does a better job of normalizing numbers, so we recommend using it for phone numbers and other cases where number normalization is important.
For low-latency or Agents Platform applications, best practice is to have your LLM normalize the text before passing it to the TTS model, or use the apply_text_normalization parameter (Enterprise plans only for v2.5 models).
Model selection guide
For guidance on which model best fits your requirements and use case, see the model selection guide.
Requirements
Use eleven_multilingual_v2
Best for high-fidelity audio output with rich emotional expression
Use Flash models
Optimized for real-time applications (~75ms latency)
Use either either eleven_multilingual_v2 or eleven_flash_v2_5
Both support up to 32 languages
Use eleven_flash_v2_5
Good balance between quality and speed
Use case
Use eleven_multilingual_v2
Ideal for professional content, audiobooks & video narration.
Use eleven_flash_v2_5, eleven_flash_v2 oreleven_multilingual_v2
Perfect for real-time conversational applications
Use eleven_multilingual_sts_v2
Specialized for Speech-to-Speech conversion
Character limits
The maximum number of characters supported in a single text-to-speech request varies by model.
Scribe v2
Scribe v2 is our state-of-the-art speech recognition model designed for accurate transcription across 90+ languages. It provides precise word-level timestamps and advanced features like speaker diarization and dynamic audio tagging.
This model excels in scenarios requiring accurate speech-to-text conversion:
- Transcription Services: Perfect for converting audio/video content to text
- Meeting Documentation: Ideal for capturing and documenting conversations
- Content Analysis: Well-suited for audio content processing and analysis
- Multilingual Recognition: Supports accurate transcription across 90+ languages
Key features:
- Accurate transcription with word-level timestamps
- Speaker diarization for multi-speaker audio
- Dynamic audio tagging for enhanced context
- Support for 90+ languages
- Entity detection
- Keyterm prompting
Read more about Scribe v2 here.
Scribe v2 Realtime
Scribe v2 Realtime, our fastest and most accurate live speech recognition model, delivers state-of-the-art accuracy in over 90 languages with an ultra-low 150ms of latency.
This model excels in conversational use cases:
- Live meeting transcription: Perfect for realtime transcription
- AI Agents: Ideal for live conversations
- Multilingual Recognition: Supports accurate transcription across 90+ languages with automatic language recognition
Key features:
- Ultra-low latency: Get partial transcriptions in ~150 milliseconds
- Streaming support: Send audio in chunks while receiving transcripts in real-time
- Multiple audio formats: Support for PCM (8kHz to 48kHz) and μ-law encoding
- Voice Activity Detection (VAD): Automatic speech segmentation based on silence detection
- Manual commit control: Full control over when to finalize transcript segments
Read more about Scribe v2 Realtime here.
Eleven Music
Eleven Music is our studio-grade music generation model. It allows you to generate music with natural language prompts in any style.
This model is excellent for the following scenarios:
- Game Soundtracks: Create immersive soundtracks for games
- Podcast Backgrounds: Enhance podcasts with professional music
- Marketing: Add background music to ad reels
Key features:
- Complete control over genre, style, and structure
- Vocals or just instrumental
- Multilingual, including English, Spanish, German, Japanese and more
- Edit the sound and lyrics of individual sections or the whole song
Read more about Eleven Music here.
Concurrency and priority
Your subscription plan determines how many requests can be processed simultaneously and the priority level of your requests in the queue. Speech to Text has an elevated concurrency limit. Once the concurrency limit is met, subsequent requests are processed in a queue alongside lower-priority requests. In practice this typically only adds ~50ms of latency.
The response headers include current-concurrent-requests and maximum-concurrent-requests which you can use to monitor your concurrency.
API requests per minute vs concurrent requests
It’s important to understand that API requests per minute and concurrent requests are different metrics that depend on your usage patterns.
API requests per minute can be different from concurrent requests since it depends on the length of time for each request and how the requests are batched.
Example 1: Spaced requests If you had 180 requests per minute that each took 1 second to complete and you sent them each 0.33 seconds apart, the max concurrent requests would be 3 and the average would be 3 since there would always be 3 in flight.
Example 2: Batched requests However, if you had a different usage pattern such as 180 requests per minute that each took 3 seconds to complete but all fired at once, the max concurrent requests would be 180 and the average would be 9 (first 3 seconds of the minute saw 180 requests at once, final 57 seconds saw 0 requests).
Since our system cares about concurrency, requests per minute matter less than how long each of the requests take and the pattern of when they are sent.
How endpoint requests are made impacts concurrency limits:
- With HTTP, each request counts individually toward your concurrency limit.
- With a WebSocket, only the time where our model is generating audio counts towards your concurrency limit, this means a for most of the time an open websocket doesn’t count towards your concurrency limit at all.
Understanding concurrency limits
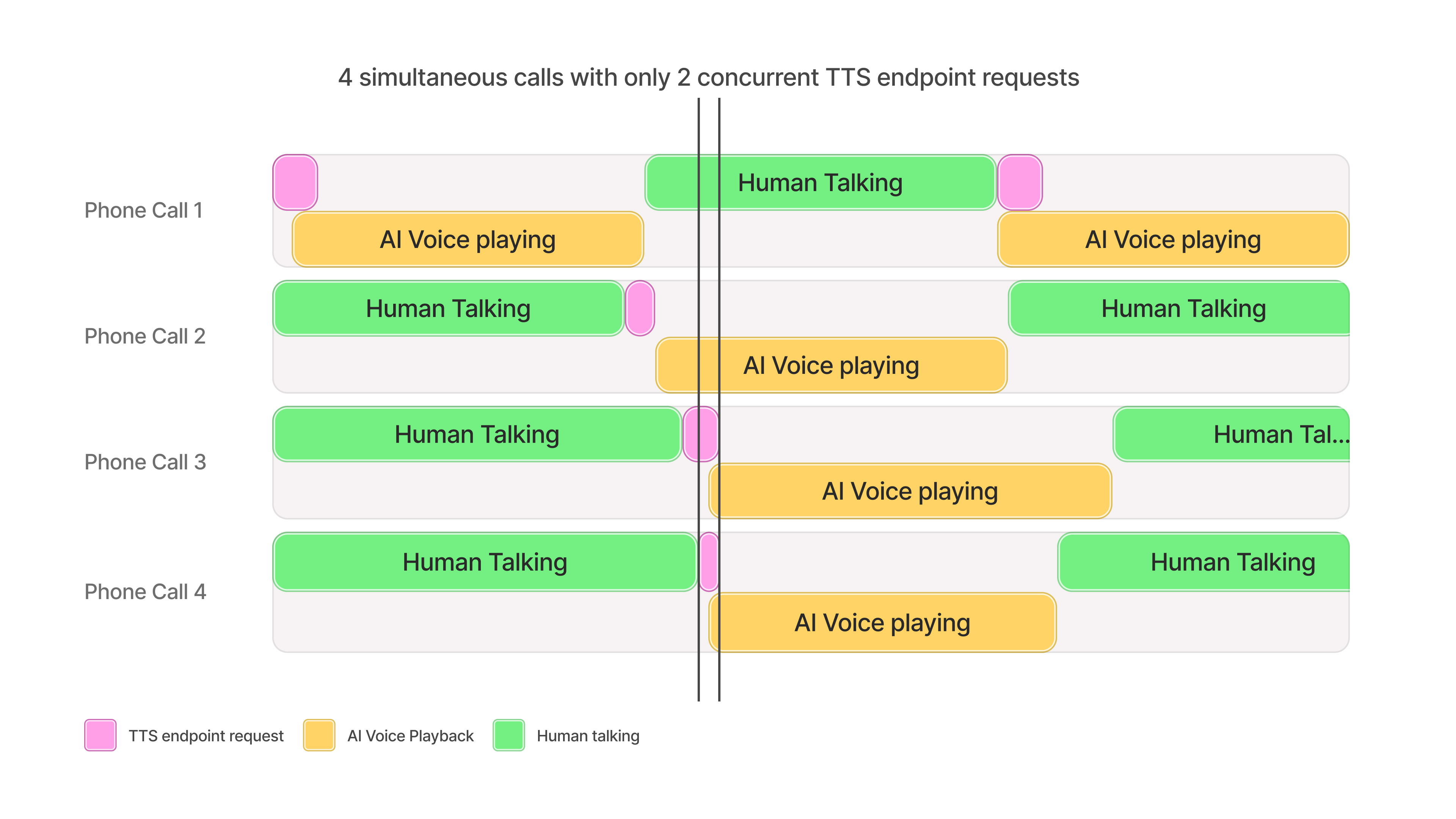
The concurrency limit associated with your plan should not be interpreted as the maximum number of simultaneous conversations, phone calls character voiceovers, etc that can be handled at once. The actual number depends on several factors, including the specific AI voices used and the characteristics of the use case.
As a general rule of thumb, a concurrency limit of 5 can typically support up to approximately 100 simultaneous audio broadcasts.
This is because of the speed it takes for audio to be generated relative to the time it takes for the TTS request to be processed. The diagram below is an example of how 4 concurrent calls with different users can be facilitated while only hitting 2 concurrent requests.
Building AI Voice Agents
Where TTS is used to facilitate dialogue, a concurrency limit of 5 can support about 100 broadcasts for balanced conversations between AI agents and human participants.
For use cases in which the AI agent speaks less frequently than the human, such as customer support interactions, more than 100 simultaneous conversations could be supported.
Character voiceovers
Generally, more than 100 simultaneous character voiceovers can be supported for a concurrency limit of 5.
The number can vary depending on the character’s dialogue frequency, the length of pauses, and in-game actions between lines.
Live Dubbing
Concurrent dubbing streams generally follow the provided heuristic.
If the broadcast involves periods of conversational pauses (e.g. because of a soundtrack, visual scenes, etc), more simultaneous dubbing streams than the suggestion may be possible.
If you exceed your plan’s concurrency limits at any point and you are on the Enterprise plan, model requests may still succeed, albeit slower, on a best efforts basis depending on available capacity.
To increase your concurrency limit & queue priority, upgrade your subscription plan.
Enterprise customers can request a higher concurrency limit by contacting their account manager.
Scale testing concurrency limits
Scale testing can be useful to identify client side scaling issues and to verify concurrency limits are set correctly for your usecase.
It is heavily recommended to test end-to-end workflows as close to real world usage as possible, simulating and measuring how many users can be supported is the recommended methodology for achieving this. It is important to:
- Simulate users, not raw requests
- Simulate typical user behavior such as waiting for audio playback, user speaking or transcription to finish before making requests
- Ramp up the number of users slowly over a period of minutes
- Introduce randomness to request timings and to the size of requests
- Capture latency metrics and any returned error codes from the API
For example, to test an agent system designed to support 100 simultaneous conversations you would create up to 100 individual “users” each simulating a conversation. Conversations typically consist of a repeating cycle of ~10 seconds of user talking, followed by the TTS API call for ~150 characters, followed by ~10 seconds of audio playback to the user. Therefore, each user should follow the pattern of making a websocket Text-to-Speech API call for 150 characters of text every 20 seconds, with a small amount of randomness introduced to the wait period and the number of characters requested. The test would consist of spawning one user per second until 100 exist and then testing for 10 minutes in total to test overall stability.
Scale testing script example
This example uses locust as the testing framework with direct API calls to the ElevenLabs API.
It follows the example listed above, testing a conversational agent system with each user sending 1 request every 20 seconds.