AlphaPoznaj Eleven v3.
Poznaj Eleven v3.
Najbardziej ekspresyjny model Text to Speech.
Wypróbuj próbki
Zasilane przez Eleven v3 (alpha)
Kontroluj emocje, sposób i kierunek za pomocą znaczników audio
Twórz kontrolowaną, ekspresyjną mowę z warstwami emocji, wydarzeniami audio i wciągającymi pejzażami dźwiękowymi.

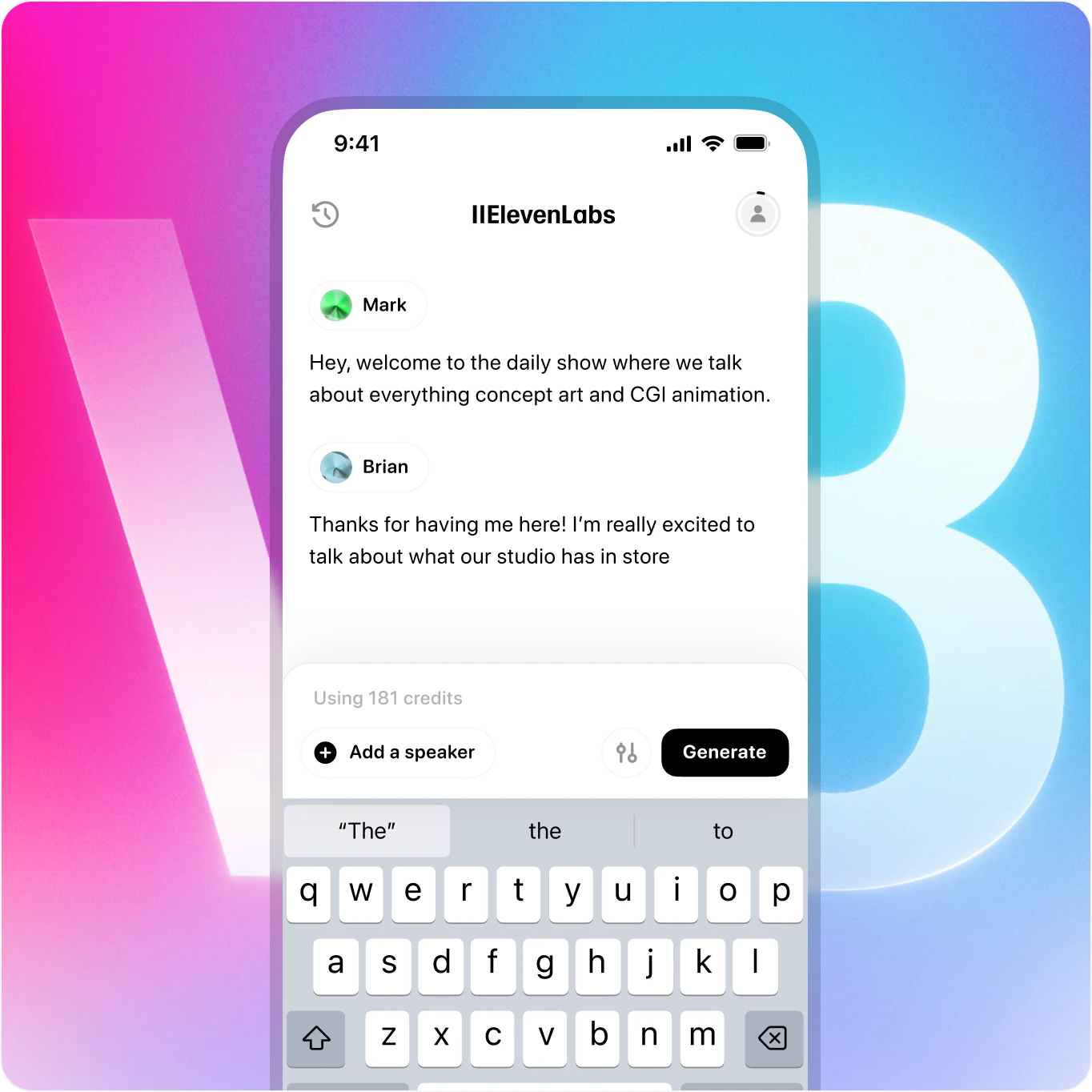
Generuj dynamiczne rozmowy między wieloma mówcami
Twórz rozmowy audio, w których mówcy dzielą się kontekstem i emocjami, sprawiając, że generowany dialog brzmi naturalnie i ludzko.

Zabierz v3 wszędzie - teraz dostępne na telefonie
Twórz realistyczną mowę z bogatymi emocjami - prosto z telefonu. Nasz głos AI zapewnia jakość studyjną z dowolnego miejsca.
Ludzka mowa w ponad 70 językach
Dotrzyj do globalnej publiczności z ekspresyjną i zniuansowaną mową w każdym głównym języku.

Angielski

Chiński

Hiszpański

Francuski

Portugalski

Niemiecki

Japoński

Włoski
Poznaj nasz najbardziej ekspresyjny model z emocjonalną głębią i bogatym przekazem.
Eleven v3 (alpha) różni się od innych modeli ElevenLabs, oferując szeroki zakres dynamiczny kontrolowany za pomocą znaczników audio.
Wielu mówców (tryb dialogowy)
Obsługa tagów
Pełen zakres emocji, wydarzeń, ogólny kierunek, rytm
Standardowe pauzy, przerwy
Języki
70+
29
Twórz z Eleven v3 API
Generuj realistyczną mowę w ponad 70 językach z emocjami, kierunkiem i kontrolą wielu mówców, używając wbudowanych znaczników audio.

| import { ElevenLabsClient, play } from '@elevenlabs/elevenlabs-js'; |
| import 'dotenv/config'; |
| const elevenlabs = new ElevenLabsClient(); |
| const voiceId = 'JBFqnCBsd6RMkjVDRZzb'; |
| const audio = await elevenlabs.textToSpeech.convert(voiceId, { |
| text: '[powoli] Wtedy... [chichot] nie mieliśmy telefonów. |
| [szeptem] Tylko drogi gruntowe i [kaszel] wielkie marzenia. [smutno] Potem to się stało', |
| modelId: 'eleven_v3', |
| outputFormat: 'mp3_44100_128', |
| }); |
| await play(audio); |
Zostały wygenerowane wyłącznie modelem Eleven v3.
Text to Dialogue łączy wiele głosów, tworząc płynną interakcję między nimi. Dopasowując prozodię, zakres emocji i korzystając z tagów audio, Text to Dialogue to krok naprzód w generowaniu angażujących rozmów.
Publiczne API dla Eleven v3 (alpha) już wkrótce. Aby uzyskać wcześniejszy dostęp, skontaktuj się z działem sprzedaży.
Eleven v3 obsługuje szeroką gamę tagów audio, które są częściowo zależne od głosu i kontekstu. Przeczytaj przewodnik po promptach aby dowiedzieć się więcej.
Afrikaans (afr), arabski (ara), ormiański (hye), asamski (asm), azerski (aze), białoruski (bel), bengalski (ben), bośniacki (bos), bułgarski (bul), kataloński (cat), cebuański (ceb), cziczewa (nya), chorwacki (hrv), czeski (ces), duński (dan), niderlandzki (nld), angielski (eng), estoński (est), filipiński (fil), fiński (fin), francuski (fra), galicyjski (glg), gruziński (kat), niemiecki (deu), grecki (ell), gudżarati (guj), hausa (hau), hebrajski (heb), hindi (hin), węgierski (hun), islandzki (isl), indonezyjski (ind), irlandzki (gle), włoski (ita), japoński (jpn), jawajski (jav), kannada (kan), kazachski (kaz), kirgiski (kir), koreański (kor), łotewski (lav), lingala (lin), litewski (lit), luksemburski (ltz), macedoński (mkd), malajski (msa), malajalam (mal), mandaryński chiński (cmn), marathi (mar), nepalski (nep), norweski (nor), paszto (pus), perski (fas), polski (pol), portugalski (por), pendżabski (pan), rumuński (ron), rosyjski (rus), serbski (srp), sindhi (snd), słowacki (slk), słoweński (slv), somalijski (som), hiszpański (spa), suahili (swa), szwedzki (swe), tamilski (tam), telugu (tel), tajski (tha), turecki (tur), ukraiński (ukr), urdu (urd), wietnamski (vie), walijski (cym)